Em 4 de outubro de 2021, os serviços do Facebook foram gradualmente desativados e, de repente, às 15:39 UTC. Demorou quase seis horas para restaurar o serviço ao normal. Com mais de 3,5 bilhões de usuários enfrentando um longo tempo de inatividade usando um ou vários produtos do Facebook, Inc. (agora conhecido como Meta Platforms, Inc.), as conversas inundaram a Internet sobre o que causou os problemas de tempo de inatividade no serviço de rede social americano. Este artigo tenta delinear os eventos que levaram à interrupção e ajudar organizações grandes e pequenas a aprender com a quebra.
Linha do tempo
- Durante as atividades regulares de manutenção de rede, os engenheiros do Facebook aplicaram um patch aos roteadores de rede em sua rede de backbone, desligando-os involuntariamente.
- Os comandos de auditoria que geralmente evitam esses erros continham um bug, tornando esta uma correção ineficaz.
- O Facebook opera sua própria rede de backbone que armazena todos os seus dados e os encaminha para a Internet por meio de várias portas de entrada. Essa alteração de configuração defeituosa nos roteadores de backbone interrompeu todas as comunicações internas.
- Isso resultou em um efeito cascata em sua intranet e, um por um, a rede tornou-se insalubre, parou de retransmitir sua presença para a Internet e, eventualmente, todos os aplicativos e serviços da empresa, incluindo pontos de acesso internos, saíram da rede.
- Como resultado, um recurso que respondia às próprias consultas DNS tornou-se inacessível. Os erros de resolução de DNS dispararam e, em questão de minutos, uma por uma, todas as entradas de conteúdo do Facebook em todo o mundo estavam virtualmente inacessíveis. O Facebook foi repentinamente fora da grade, e o domínio foi até listado como “disponível” para venda por um curto período de tempo. “O Facebook basicamente trancou suas chaves no carro”, tuitou Jonathan Zittrain, diretor do Centro Berkman Klein de Harvard para Internet e Sociedade.
Qual foi a resposta inicial?
“Nossas ferramentas e sistemas internos complicaram as tentativas [de nossas equipes de TI] de diagnosticar rapidamente e resolver o problema”, explicou Santosh Janardhan, vice-presidente de infraestrutura da Facebook Inc., acrescentando: “[Nossa equipe de TI] identificou a causa raiz como um defeito de configuração e descartou qualquer atividade maliciosa ou violação de dados. ”
Por que e como essa grande interrupção aconteceu?
O Border Gateway Protocol (BGP) é o sistema postal da internet, onde, por meio de protocolos de roteamento, empresas como o Facebook podem anunciar seus sistemas autônomos com as demais empresas de internet. Em outras palavras, o BGP ajuda as redes a escolher a melhor forma de chegar a qualquer outra rede, como um serviço postal.
A internet é uma rede de redes, por isso é vital que os pares se anunciem com frequência para permanecer nos caminhos do DNS que permitem que usuários em todo o mundo cheguem a seus servidores. Dentro do Facebook está uma vasta rede que a empresa chama de backbone, que é o investimento de longo prazo da empresa e o desenvolvimento de sua própria intranet que se estende por todo o mundo, conectando seus data centers por meio de redes de fibra.
As instalações se conectam entre si por meio dessa rede de backbone por meio de roteadores. Nesses roteadores, em 4 de outubro, um trabalho de manutenção de rotina desligou sem querer todas as conexões na rede de backbone. Uma analogia é quando a cozinha é isolada do restaurante, resultando em comensais impacientes e famintos exigindo refeições.
Como foi a recuperação?
Durante a jornada de reparo, os engenheiros acharam difícil acessar seus data centers, pois as entradas foram bloqueadas devido a falha de rede e as ferramentas de reparo internas estavam inutilizáveis. Como último recurso, o pessoal foi implantado nos centros de dados para depurar fisicamente e reiniciar os sistemas. Esse processo foi projetado para ser desafiador do ponto de vista da segurança, por isso levou mais tempo para resolvê-lo. Depois que a equipe de TI consertou, a rede voltou a funcionar.
O que podemos aprender com a interrupção?
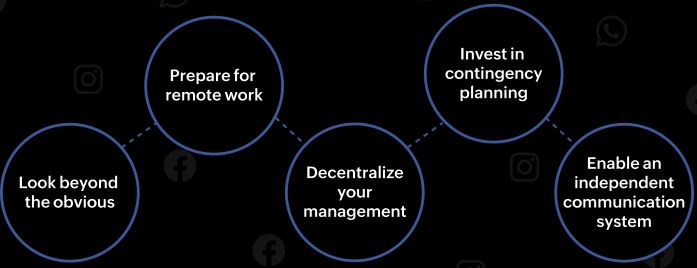
1. Olhe além do óbvio para encontrar a causa raiz
Há uma piada de TI que, quando um site cai, a suspeita usual é o DNS. No entanto, neste caso, a interrupção do DNS foi apenas um sintoma: a causa raiz foi a conexão interrompida entre o peering de BGP e os roteadores de peering. Peering é o método que duas redes usam para se conectar para trocar tráfego diretamente, sem a necessidade de uma operadora de terceiros. As mudanças de configuração nesses roteadores de peering do Facebook levaram a uma quebra nas rotas de rede saudáveis e, quando permaneceram quebradas por um período, as próprias rotas tornaram-se disfuncionais e praticamente inexistentes.
2. Prepare-se para os desafios de trabalho remoto COVID-19
Em sua tentativa de recuperação, os funcionários remotos tentaram obter acesso a roteadores de peering para implementar correções. No entanto, as tentativas eram frequentemente frustradas devido ao desafio logístico de as pessoas ficarem sem acesso aos data centers onde as correções precisavam ser implementadas. A escassez de força de trabalho causada por uma pandemia foi um grande desafio para o Facebook Inc, pois tinha recursos escassos já em implantação quando o incidente aconteceu. Com os funcionários sendo bloqueados devido a problemas de segurança, a escassez de pessoal técnico disponível prolongou o tempo necessário para corrigir erros e operações de rede.
3. Objetivo de uma gestão descentralizada
A empresa de quase um trilhão de dólares sofreu uma interrupção em todos os seus aplicativos devido a uma estrutura de política de centralização que a tornou vulnerável. Especialistas dizem que um controle descentralizado de ativos de aplicativos com uma demarcação clara entre os mesmos aplicativos de propriedade da empresa com sua própria cadência pode ter ajudado a evitar uma interrupção completa. Pedidos de gestão descentralizada ganharam preferência nos últimos anos por mais razões do que antitruste. Essa abordagem garante que nem todos os ovos estejam em uma única cesta, em vez de fornecer opções para corrigir problemas em vários níveis isolados, em vez de afetar sistemas inteiros de uma vez, o que pode tornar a solução de problemas incontrolável.
Durante o tempo de inatividade, talvez devido às raízes da arquitetura diferente do Instagram, ele poderia passar as solicitações de conexão TCP / TLS com sucesso. Os outros serviços, WhatsApp, Facebook e Messenger, estavam retornando um erro “502 gateway inválido”. Ainda assim, devido à forma como o Instagram foi conectado ao backbone do Facebook, o site não carregou para os usuários finais. Isso levou à opinião entre os especialistas em TI de que, se uma grande empresa como o Facebook dividir suas divisões e gerenciá-las individualmente, pode evitar uma paralisação completa que paralisa todo o ecossistema.
4. Invista em um planejamento de contingência robusto
Grande poder traz grandes riscos. Embora o Facebook tenha conduzido exercícios, como seus “simulados” que foram desenvolvidos para preparar sua infraestrutura para resistir a picos repentinos nas solicitações dos usuários ou no consumo de energia, a empresa ainda se encontrava em uma posição difícil devido à natureza sem precedentes do erro. Investir em mais planejamento de contingência baseado em risco beneficia as organizações durante situações críticas.
5. Habilite um sistema de comunicação independente
Quando todos os canais de comunicação são interrompidos em seu data center, é importante iniciar um sistema de comunicação instantânea de terceiros isolado. Quando seus centros de dados estão inativos, o StatusIQ do Site24x7 , uma página de aconselhamento hospedada fora de suas instalações, economiza o dia alertando e informando imediatamente os visitantes do site. É como ter um rádio HAM ou um walkie-talkie disponível durante os momentos de crise.
Um canal de comunicação confiável permite que sua equipe se comunique sem problemas e informe os clientes sobre o tempo de inatividade e o plano de recuperação. O StatusIQ opera independentemente de nuvens públicas, o que garante que ele permaneça ativo mesmo quando você não está trabalhando. Suporte adicional é fornecido pelo Site 24×7 por meio de sua integração fluida com Cliq, o aplicativo de bate-papo de negócios e equipe desenvolvido com recursos de comunicação ricos.
A solução de monitoramento de DNS do Site24x7 ajuda você a pesquisar o status de DNS de seus sites em mais de 110 locais globais. Ele ajuda a eliminar possíveis erros de resolução de domínio em seus servidores críticos, garantindo que você fique por dentro das interrupções e das preocupações com o desempenho.
O gerenciamento de configuração de rede do Site24x7 ajuda os administradores de TI a fazer backup de forma eficiente das configurações do roteador de rede para que possam ser restauradas imediatamente, conforme necessário.
O monitoramento de sites é um jogo de soma zero, pois a experiência do usuário e o valor da marca de uma organização costumam sofrer um impacto instantâneo quando as infraestruturas de TI são desativadas ou atacadas. Para recursos abrangentes e avançados de monitoramento de sites de ponta a ponta, visite o pacote de monitoramento de sites do Site24x7. O Site24x7 garante a disponibilidade máxima de todos os seus sites para visitantes em todo o mundo e ajuda os webmasters e administradores de TI a obter uma vantagem proativa para restaurar serviços e impedir ataques para garantir a melhor experiência do usuário.
Conheça na prática como o Site24x7 pode ajudar você e o seu negócio a entregarem uma melhor experiência á seus clientes internos e externos. Nossos técnicos estão disponíveis para te apresentar a melhor solução de monitoramento em nuvem para sua infraestrutura, conte sempre com o apoio da equipe ACSoftware.
ACSoftware / Figo Software seu Distribuidor e Revenda ManageEngine no Brasil
Fone (11) 4063 1007 – Vendas (11) 4063 9639