Em 21 de junho de 2022, o provedor de rede de entrega de conteúdo global (CDN) com sede nos EUA e a empresa de segurança Cloudflare sofreu uma interrupção às 6h27 UTC que durou até 7h42. A interrupção foi causada por um erro de configuração de rede que afetou 19 locais de data centers da Cloudflare — Amsterdã, Atlanta, Ashburn, Chicago, Frankfurt, Londres, Los Angeles, Madri, Manchester, Miami, Milão, Mumbai, Newark, Osaka, São Paulo, San Jose, Cingapura, Sydney, Tóquio. A interrupção teve um impacto mundial, desabilitando o acesso a muitos aplicativos, como o Discord, para usuários atendidos por esses data centers.
Background
A Cloudflare é uma importante CDN que fornece às empresas uma entrega rápida e confiável de conteúdo em seus sites, empregando uma malha de servidores de borda conectados por meio de servidores de coluna para fornecer dados. Para ser acessível aos usuários pela Internet, a Cloudflare usa o protocolo de gateway de borda (BGP) , o protocolo de roteamento da Internet.
A Cloudflare possibilita o acesso global a grande parte da internet, mantendo suas próprias rotas para BGP. BGP é o protocolo de roteamento da internet, também chamado de rede de correios da internet. O BGP permite uma maneira lógica para os sistemas encontrarem a rota mais fácil para transferir dados. A forma como o BGP se propaga é determinada pelas políticas de publicidade do BGP definidas pelos operadores. Essas políticas são avaliadas periodicamente e a Cloudflare contribui para mantê-las.
Como parte de seus esforços contínuos para atualizar seus serviços existentes, a Cloudflare implementou uma nova mudança de arquitetura em 21 de junho em seus 19 data centers afetados. Uma camada espinhal de servidores estava sendo implementada para melhorar a malha de servidores de borda, projetada para ajudar a tornar a infraestrutura de entrega de conteúdo da Cloudflare mais resiliente e flexível.
Ao executar o código para atualização, um erro no código de configuração de rede afetou a sequência de anúncios do BGP, fazendo com que os endereços IP da Cloudflare fossem retirados da Internet. Para complicar ainda mais a situação, esse erro também impediu que os engenheiros da Cloudflare se conectassem aos data centers afetados para reverter a alteração problemática.
A configuração incorreta no formato diff reordenou os termos no prefixo BGP, interrompendo a própria publicidade, removendo o acesso aos locais afetados e impedindo que os servidores chegassem aos servidores de origem. O balanceador de carga interno da Cloudflare também falhou e sobrecarregou clusters menores, amplificando os problemas.
Apesar desses desafios, a Cloudflare chegou à causa raiz rapidamente, comunicou o status da recuperação de forma eficaz e executou um procedimento de backup para restaurar os serviços na próxima hora.
O impacto
- A interrupção afetou significativamente o acesso à Internet para muitos aplicativos que dependem da Cloudflare para a entrega de conteúdo a usuários em todo o mundo, incluindo Discord, Shopify, Fitbit e FTX.
- Um erro de gateway incorreto 502 (o servidor que você está acessando não está se conectando a outros servidores para habilitar o acesso) apareceu para os usuários. Curiosamente, muitos detectores de tempo de inatividade também estavam inativos, pois dependiam da Cloudflare.
- Embora 5% da rede Cloudflare tenha sido atingida, a interrupção teve um impacto desproporcional, afetando 50% do total de solicitações, atrasando ou negando o acesso ao site a milhões de usuários em todo o mundo.
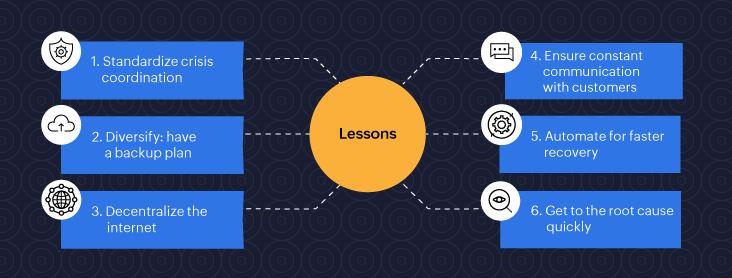
Aprendizados
1: Cloudflare lista esses aprendizados do incidente:
- Aborde as lacunas processuais para detectar erros desde o início.
- Redesenhe a arquitetura para descartar erros não intencionais no nível do design.
- Explore as oportunidades de automação para melhorar e implementar lançamentos escalonados para atualizações críticas, como alterações de configuração de rede.
- Implemente um fluxo de trabalho automatizado de reversão de confirmação de confirmação para reverter instantaneamente para o estado de funcionamento anterior quando ocorrer uma interrupção para reduzir o tempo de reparo e diminuir o impacto nos negócios.
2: Padronizar a coordenação de crise: A Cloudflare afirmou em seu blog pós-incidente que o retorno ao normal foi adiado porque os engenheiros de rede “passaram por cima das mudanças uns dos outros, revertendo as reversões anteriores, fazendo com que o problema reaparecesse esporadicamente”. Isso exige procedimentos operacionais robustos e padronizados para estabelecer regras claras sobre acesso, controle e escalonamento com comunicação constante.
3: Chegue rapidamente à causa raiz: Aprofunde-se rapidamente na causa raiz. Ter uma equipe de manutenção completa ajuda a manter o controle dos erros para detalhar a causa raiz e corrigir o problema mais rapidamente.
4: Apelo a uma Internet descentralizada: Existe uma preocupação generalizada de que a Internet tenha se tornado cada vez mais centralizada, com um punhado de empresas de nuvem e provedores de infraestrutura sendo responsáveis por conectar o globo. Muitos incidentes recentes, como a interrupção do Fastly em junho de 2021, a interrupção da AWS em junho de 2022 e a interrupção do Facebook em outubro de 2021 , tiveram um impacto significativo nos usuários da Internet em todo o mundo, provocando conversas sobre a necessidade de descentralizar a Internet.
5: Diversifique e crie resiliência: as empresas que executam serviços críticos podem explorar maneiras de mitigar as dependências de um único fornecedor, diversificar e incluir um plano de backup robusto para fornecer seus serviços de negócios sem interrupções. Durante o tempo de inatividade da CDN, as empresas podem habilitar o acesso independente da CDN para sites, permitindo conexões lentas, embora funcionais, durante o período de reparo.
6: Garanta uma comunicação constante com os clientes: Aproveite as páginas de comunicação de status ricas que informam os usuários sobre como os sites estão funcionando com explicações sobre o caminho de recuperação. O StatusIQ do Site24x7 permite comunicação transparente e instantânea por meio de páginas de comunicação de status hospedadas independentemente com opções para personalizá-lo para se adequar ao idioma de cada marca. Isso reduz a ansiedade durante o tempo de inatividade, reduz o número de tíquetes de suporte, cria confiança e protege a reputação da marca.
A recente interrupção da Cloudflare é uma oportunidade para os departamentos de TI reavaliarem a importância de mudanças robustas de infraestrutura e a necessidade de garantir um plano de restauração para partes críticas da Internet das quais milhões de usuários dependem.
Você pode testar o Site24x7 dentro da sua empresa sem custo algum. Que tal realizar esse teste agora?
Conheça na prática como o Site24x7 pode ajudar você e o seu negócio. Nossos técnicos estão disponíveis para te apresentar a melhor solução de monitoramento em nuvem para sua infraestrutura, conte sempre com o apoio da equipe ACSoftware.
ACSoftware / Figo Software seu Distribuidor e Revenda ManageEngine no Brasil
Fone (11) 4063 1007 – Vendas (11) 4063 9639